Google Cloud DataProc Lab to
Setup Jobs for Hadoop and Spark
Working with Cloud Dataproc.
Lab objectives:
- To show you just how easy it is to create a Cloud Dataproc cluster and use it to complete a Spark job.
- We'll use one of the example scripts that is bundled with Apache Spark that will estimate the value of Pi.

Method used:
- Monte Carlo method.
Simplistic explanation of Monte Carlo method:
- We take a quadrant of a circle, then generate a number of uniformly distributed random plotted points.
- The points can fall anywhere within the square.
- So some will fall inside the curve of our circle and some won't.
- If we divide the number of points within the circle by the total number of points, we should get a value that is an approximate ratio.
- We know the area of the original square, so we multiply it by that ratio to get the value of Pi.

Steps:
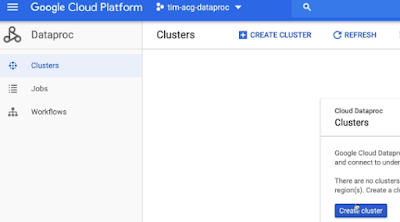
- Go to GCP project and the Cloud Console.
- Go straight to the menu and locate Dataproc in the big data section.
- The first time you load Dataproc, you'll be prompted to enable the Cloud Dataproc API. Just click Enable API.

- Click Create Cluster to create our first cluster.
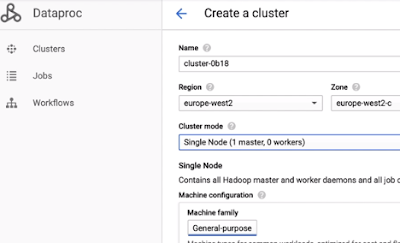
- The console will suggest a name for the cluster. You can change this if you like.
- Pick a region that's near to you. I'm going to go with europe-west2.
- Dataproc will then pick a zone for me.
- We'll change the cluster mode to Single Node.
- We'll leave the machine type as the default here, which is an n1-standard-4, including the service charge for Dataproc.
- This should cost under 20 cents for 1 hour and you should finish this lab easily in that time.
- Scroll down and click Create.
What happens in background Now:
- Dataproc is now provisioning a compute engine VM for us and installing and configuring Hadoop and Spark. This will take a few minutes.
- The cluster is now ready to get to work without us having to do any configuration work at all.
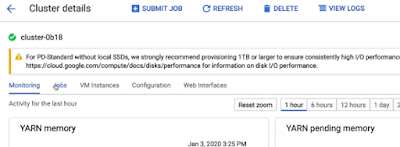
- If we select our cluster, we can see monitoring dashboards that will show us amongst other things our YARN and HDFS utilization.
Let's submit our first job.
- Click on Jobs and Submit Job.
- The first thing we need to do is change the region to match the one where we just built our cluster.
- That's europe-west2 in my case. This will then automatically populate the cluster selection dropdown.
- And of course, we only have one cluster, so it's already selected.
- Under job type, you can see the many different types of jobs that Dataproc is configured to run.
- We're going to select Spark. Spark jobs are written in Java or Scala.
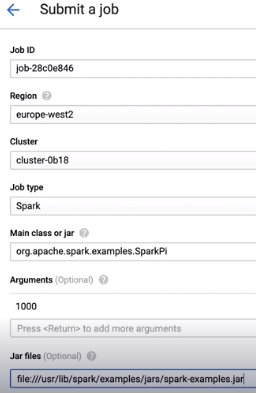
- So we next need to provide the name of the main class to run.
- We're going to use one of the built-in examples, org.apache.spark.examples.SparkPi.
- As an argument, we pass in the number 1,000. The Monte Carlo method estimates the value of Pi by plotting points on a graph.
- So here we're telling Spark to plot 1,000 points. This should give us an accuracy to about three decimal places.
- We also need to tell Spark where to find this main class, which is in the local file system in the examples directory.
- We add this in the Jar Files section. Instead of using a local file here, we could have also specified a cloud storage location or a path in HDFS.
- We don't need to provide any supplemental jar files or other properties or labels, so we can go ahead and click Submit.
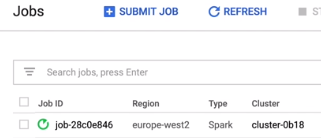
- We're now taken to the jobs page where we can see our job has the status of running.
- If we click on our job, we can watch the console output as it runs.
- We can see that a new Spark application is being created and submitted to YARN.
- It will take about a minute for the job to complete,
- Click on Jobs and Submit Job.
- The first thing we need to do is change the region to match the one where we just built our cluster.
- That's europe-west2 in my case. This will then automatically populate the cluster selection dropdown.
- And of course, we only have one cluster, so it's already selected.
- Under job type, you can see the many different types of jobs that Dataproc is configured to run.
- We're going to select Spark. Spark jobs are written in Java or Scala.
- So we next need to provide the name of the main class to run.
- We're going to use one of the built-in examples, org.apache.spark.examples.SparkPi.
- As an argument, we pass in the number 1,000. The Monte Carlo method estimates the value of Pi by plotting points on a graph.
- So here we're telling Spark to plot 1,000 points. This should give us an accuracy to about three decimal places.
- We also need to tell Spark where to find this main class, which is in the local file system in the examples directory.
- We add this in the Jar Files section. Instead of using a local file here, we could have also specified a cloud storage location or a path in HDFS.
- We don't need to provide any supplemental jar files or other properties or labels, so we can go ahead and click Submit.
- We're now taken to the jobs page where we can see our job has the status of running.
- If we click on our job, we can watch the console output as it runs.
- We can see that a new Spark application is being created and submitted to YARN.
- It will take about a minute for the job to complete,
- It will take about a minute for the job to complete,
- You may also experience an audit GCP Console bug where it looks like the job is still waiting, but if you click the page, it will refresh and you'll see it's actually already finished.
- So here's our result, Pi is 3.141, and here's where it goes off track a bit, but we only used 1,000 points for our estimate.
- Feel free to rerun this job with more points to see how more accurate the estimation gets.
- Now that we've finished, we'll delete our cluster.
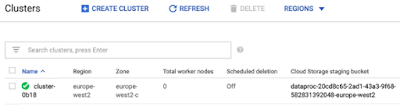
- Go back to the clusters page, tick the box next to your cluster, click Delete and Confirm.
- One useful thing about Dataproc in the Cloud Console here is that even after our clusters have been deleted, the logs of our jobs persist.
- We can go back into the job section and revisit the output of the job we just ran, even though the cluster itself has been deleted.
Jobs can also be submitted via the G Cloud command line tool or using the Dataproc API.
Once Work is finished, make sure you delete the Cluster

No comments:
Write commentsPlease do not enter spam links