Cloud Dataproc in GCP
What is Cloud Dataproc?
- Cloud Dataproc is a managed cluster service in GCP.
- It is used for running Hadoop and Spark jobs.
- It takes away all of the hassle of running your own clusters and VMs, and managing storage, and sets up a managed service that's ready to accept jobs that you simply send to it.

Why would you want to use a managed service?
- There is lot happen behind the scenes toil of getting the Hadoop and spark services up and running. you need to provision machines, giving considerations to things like CPU, RAM, and disk sizing.
- Then install all the necessary software. And then configure these machines to set up a working cluster.
- What about once we need to grow our cluster to handle a larger workload or dataset?
- What about all the times your cluster isn't busy? It's just sat there, incurring costs for all those wasted resources.
- In general, in the cloud, managed services are always preferable.
- Cloud Dataproc provides managed clusters for Spark and Hadoop.
- Using parameters you define it will create a master node, running the YARN resource manager and HDFS named node, and worker nodes, running the yarn node manager and HDFS data nodes.
- Each node comes automatically pre-installed with a recent stable version of Hadoop and Spark, as well as Zookeeper, Apache Hive, Pig, and Tez, and other tools such as Jupyter Notebooks,
- and a GCS connector.
- There are also additional components that can be added, or you can even create a custom image to be deployed to the VMs in your Dataproc cluster.
- All of the cluster and storage configuration is handled for you by the Dataproc service.

The most compelling feature of Dataproc.
- As a managed service, its billing model is awesome.

- Standing up a cluster ready to accept jobs takes about 90 seconds and cluster resources are billed per second with a minimum billing period of just 1 minute.
- This means you can quickly set up resources to process a dataset or scale up an existing cluster
- when you're expecting a larger than normal workload, then scale it down again, or even turn it off and only pay for what you use.
- Once your cluster is up and running, you simply submit Hadoop or Spark jobs to it, as you would with any other Hadoop or Spark service.
- Dataproc is completely interoperable and compatible with up-to-date versions of these open source tools.
- If necessary, the cluster can be designed to auto scale, to cope with the load of the job.
- Outputs can be automatically pushed to Google Cloud Storage, BigQuery, and BigTable.
- And Dataproc also integrates with Stackdriver logging and monitoring.

Setting up clusters and submitting jobs.
There are a couple of design choices to make when creating a Dataproc cluster.
Is whether to create regional or global resources.?
- Regional:
- You can isolate all the resources used for Dataproc into a specific region, such as, us-east1, or europe-west1.
- You may need to do this for a variety of compliance or performance reasons.
- When you specify a region, you can then choose the zone yourself
- or have Dataproc pick one for you.
- Global:
- This doesn't actually mean your cluster is automatically a global resource.
- It just means that it's not tied to a specific region and you can place its resources in any available zone, worldwide.

You can build 3 different types of clusters
The type of each of these machines is fully configurable, as is the amount and type of disk you provide to them.
- A single node cluster.
- A single VM that will run the master and work the processes.
- Single nodes can still provide most of the features of Dataproc.
- You're obviously just limited to the capacity of a single VM and you can't auto scale a single node cluster.

- A standard cluster.
- This comprises a master VM, which runs the YARN Resource Manager and HDFS Name Node, and 2 or more worker nodes, which each provide a YARN Node Manager and HDFS Data Node.
- With a standard cluster, you can also add additional preemptible workers.
- This is sometimes useful for large processing jobs.
- In addition to the usual caveats about using preemptible VMs, bear in mind that they also can't provide storage for HDFS.

- High availability cluster
- For long running Dataproc clusters, where you need to be able to guarantee reliability, your final option is a high availability cluster.
- This is similar to a standard cluster, except you now get 3 masters,
- with YARN and HDFS configured to run in high availability mode,
- providing uninterrupted operations in the event of any single node failure or reboot.

Submitting Jobs
- Once your cluster is up and running, you have lots of options for how to submit jobs.
- You can submit jobs using the gcloud Command Line tool from either your own computer or within cloud shell, from within the GCP Console,
- using the cloud Dataproc HTTP API, or you can even SSH into the Master Node and submit a job locally.
- Dataproc will accept several different types of job, Hadoop, Spark, SparkR, Hive, Spark SQL, Pig, Presto, and PySpark.
- Each will have their own subset of parameters and arguments that you can provide, such as the main program to run, and any additional files or properties required.

State of Jobs
- Jobs are created in a pending state, then move to a running state while they're being processed by the Dataproc agent and the YARN cluster.
- When a job is complete, it enters the done state.
- Different states can be queried by the Dataproc API or simply viewed in the GCP console.
Job Monitoring

- Stackdriver monitoring can be used to monitor the health of your Dataproc cluster.
- Notable Stackdriver metrics for Dataproc include
- Allocated memory percentage: It will show you how much of your overall cluster memory is being used by the current workload.
- Storage utilization: It will show you how much of the total available HDFS storage you have used,
- Unhealthy blocks: It should help you to identify any problems you may have with your storage.
- YARN and job output logs: It can also be redirected into Stackdriver logging for later inspection.
Advanced features of DataProc cluster setup
Dataproc nodes are pre-configured VMs, built from a Google-maintained image that includes Hadoop, Spark, and all of the common tools you need to process your big data jobs.

If we need completely different packages,
- You can create your own custom image that will be used in your cluster, instead of the default image.
- Google will provide a simple script that will create a Compute Engine VM, based on the default Dataproc image. Then apply a customization script that you've written, and finally, store the image of this new VM in Google Cloud Storage, ready to be used in your Dataproc cluster.

- You can customize a Dataproc cluster without having to completely rebuild the image it's running on. The open-source components of Dataproc, such as Hadoop and Spark,all ship with numerous configuration files. Using custom cluster properties, you can apply changes to any of the values in dozens of different configuration files, when setting up your cluster. You can leave these at the default and add custom initialization actions to your cluster. These are scripts that you can upload to a Cloud Storage bucket, which will be executed on all of the nodes in your cluster, as soon as the cluster is set up. These are commonly used for staging binaries or pre-loading any binaries that might be required for a job, rather than submitting them as part of the job itself.
- For Spark jobs, you can specify custom Java and Scala dependencies when submitting the job. This saves you from pre-compiling these dependencies on your entire cluster, when they're only going to be needed by specific Spark jobs.

Most powerful features of Cloud Dataproc is its ability to Autoscale.
- This allows you to create relatively lightweight clusters and have them automatically scale up to the demands of a job, then scale back down again, when the job is complete.
- Autoscaling policies are written in YAML, and contain the configuration for the number of primary workers, as well as secondary or preemptible workers.

- The basic autoscaling algorithm operates on YARN memory metrics, to determine when to adjust the size of the cluster. After every cooldown period elapses, the optimal number of workers is evaluated using this formula.
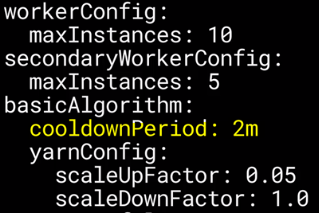
- If a worker has a high level of pending memory, it probably has more work to do to finish task. But if it has a high level of available memory, it's possible that the worker is no longer required and could be scaled down again.
- The scale-up and scale-down factors are used to calculate how many workers to add or remove if the number needs to change.
- The gracefulDecommissionTimeout is specific to YARN and sets a timeout limit for removing a node if it's still processing a task. This is a kind of failsafe, so you don't keep removing workers if they're still busy.


When to Avoid Autoscaling in DataProc

- There are some times when you should not use Dataproc Autoscaling.
- You ideally shouldn't use HDFS storage when using Autoscaling. Use Cloud Storage instead.
- If you are using Autoscaling and HDFS, you need to make sure that you have enough primary workers
- to store all of your HDFS data, so it doesn't become corrupted by a scale-down operation.
- Spark Structured Streaming is also not supported by Autoscaling. You shouldn't rely on Autoscaling to maintain idle clusters.
- If your cluster is likely to be idle for periods of time, don't rely on Autoscaling to clean up resources for you.
- Just delete the idle cluster, and create a new one the next time you need to run a job.
Automation of Dataproc clusters and jobs - a built-in feature "Workflow Templates".
- These are templates written in YAML that can specify multiple jobs, with different configurations and parameters, to be run in succession.
- A template must be created first, but won't execute any actions, until it is instantiated using the gcloud command.
- In this example, our template contains the specifications for an ephemeral cluster, which is created when our template is ins instantiated.
- Jobs are submitted to the cluster, and the cluster will be deleted, once the jobs are complete.
- We can alternatively configure our template to use an existing cluster, instead of creating a new one each time.

Advantage of Compute engines in Dataproc

- Dataproc runs on Compute Engine VMs, there are some advanced features of Compute Engine you can also take advantage of.
- You can enable local SSDs for your master and worker nodes, including preempt workers to provide much faster read and write times than persistent disk.
- This is useful for short-lived clusters utilizing HDFS storage.
- You can also attach GPUs to your nodes to assist with specific workloads, such as machine learning, which are well suited to the instruction sets of GPUs.
- the default Dataproc image doesn't contain the necessary drivers and software to use GPUs, but you can apply these with an initialization action, or create a custom cluster image.
- You also can't attach GPUs to preemptible workers.
Benefits of Cloud Dataproc is the Cloud Storage Connector.
- This allows you to run Dataproc jobs directly on data in Cloud Storage, rather than using the HDFS storage service provided by your worker nodes.
- This is not only cheaper than persistent disk storage, but you gain all the benefits of GCS, such as high availability and durability.
- This allows you to decouple your storage from the lifespan of your cluster.
- You can get rid of a cluster as soon as its work is finished, knowing your data is safely stored in Cloud Storage.

Key TakeAways
- Dataproc:
- It's a great choice for quickly migrating Hadoop and Spark workloads into Google Cloud Platform.
- There's no point in migrating to the cloud, just for the sake of migrating to the cloud.
- The biggest benefits of Dataproc over a self managed Hadoop or Spark cluster are the ease of scaling, being able to use cloud storage instead of HDFS, and the connectors to other GCP services including BigQuery and Bigtable.
- Cloud Dataflow
- It is the preferred product for ingesting big data,
- In particular for streaming workloads so you can't always assume Dataproc is going to be the right choice.
- Cloud Dataflow implements the Apache Beam SDK, so definitely look out for mentions of Beam if you are in client discussion
No comments:
Write commentsPlease do not enter spam links